1 微表情定义与技术原理
针对人们真实情绪和意图的研究始终是心理学和社会学主要研究方向。在20世纪早期,有学者开始以生理指标为基础的情绪或者意图研究。1921年加州大学John Larson发明了测谎仪,之后又出现了基于热图像、脑电信号以及功能磁共振成像等方法的生理监测方法。但这些方法的信息采集需要专门设备,而且这些评估手段基本公开,人们可以经过一定的训练来隐瞒其真实意图。与上述生理线索相比,面部表情是在人类进化过程中形成的,是人类之间传递社会信息的主要手段和直观手段。由于面部表情特征包含丰富直观的情绪信息,并且可以通过非接触的采集方式获取,因此获得人们广泛关注。
表情是情绪的主观体验的外部表现模式,分为生理表情(真实心理状态)、情绪表情(真实心理状态+伪装决策)和社交表情(理性决策和控制)等。美国Paul Ekman教授将人类的面部表情分为六类:高兴、惊讶、悲伤、愤怒、厌恶、恐惧。其中,心理学家和神经学家发现,欺骗者会通过情绪欺骗试图压抑某些反映真实情绪的信号,但却无法完全压抑,导致其真实情绪信号泄露,这便出现了微弱且快速的面部动作,即微表情。微表情则特指人类试图压抑或隐藏真实情感时泄露的非常短暂且不能自主控制的面部表情。美国著名心理学家,表情和微表情的奠基者Ekman经过研究认为,微表情具有三个特点:持续时间不超过1/5秒,能反映人的真实情感,在全人类是普遍存在的。
微表情可能是判断一个人真实情感的最有利的线索。经过几十年的理论发展和试验验证,微表情逐渐被学术界接受和认可,美国已经在这方面进行了几十年的研究工作,已被美国交通运输安全部用于多个机场的安检中,此外,在美国司法审讯、临床医学等领域也进行了应用测试。但国内在微表情的研究起步较晚,研究成果较少,而由于该领域的研究在很大程度上对于国家安全和司法实践较为重要,所能获得的国外资料较少。这种封锁在一定程度上也说明了微表情研究的重要意义和潜在价值,因此有必要加强对微表情的研究。
2 微表情检测与识别关键技术
在实际应用中,人们往往需要针对长视频中的面部表情进行分析。因此,作为一套完整实用系统,首先需要研究微表情和宏表情联合检测技术,并对检测到的面部序列进行纠正,然后以纠正过的面部序列为基础,对其中包含的情绪进行分类识别,进而建立从检测到识别的系统体系。 主要研究内容如下:
(1)基于长视频的宏表情与微表情检测研究
目前大多微表情研究仍基于对样本图像和确定视频帧的识别,而真实系统则需要从长视频中检测到微表情的出现才能进一步对微表情进行分析,由此,作为微表情研究的技术基础,首先将在微表情与宏表情检测的研究基础上,研究并刻画宏表情与微表情在时间和空间上的差异性,降低宏表情在微表情检测时的干扰影响,并通过对面部运动强度和时空约束的分析来探索实时性和可靠性的制约关系,建立优化模型进行问题求解,解决微表情和宏表情并存的检测难题,最终为实现表情变化分析提供良好的基础保障。
(2)基于人脸通用三维模型配准的正面视角表情图像合成
人脸姿态的任意性客观上造成了不同程度形变压缩的人脸形状和自遮挡的不可见纹理,这将使表情识别和分类子系统性能急剧恶化。因此,如何高效准确的对输入图像进行姿态估计是提高合成图像准确率的关键问题。对于给定的输入图像,如何协调计算复杂性和结果精确度二者的矛盾,进行关键区域的必要特征点标定,是合成正面图像的又一难点。
(3)基于多动态局部特征融合的微表情识别
微表情识别的可靠性是保障微表情分析的基础和关键,目前微表情的识别率和实时性都远远达不到真实环境下的性能要求。如何通过对微表情数据的分析,减少冗余帧的干扰和提高微表情的识别速度是识别效率的关键性技术。为此,如何探索基于纹理特征和基于运动特征对微表情的刻画程度,同时考虑到微表情在面部局部性的视觉体现,建立基于权重策略的局部纹理特征和运动特征融合的特征提取求解模型,最终实现实时可靠的微表情识别算法,为表情变化分析提供支撑。
(4)基于实时表情变化分析的行为预警
微表情识别的目的在于通过机器智能为人们提供预警参考。如何根据表情识别的结果,进行合理的表情变化预测分析,进而及时排查出可疑人员是预警系统的核心难题。研究多指标联合预警策略,保障预警的实时性和可靠性,辅助相关人员对特殊事件快速做出反应,是对情感分析所反映的潜在行为分析的有效途径。
微表情自动分析可以分为检测和识别两个过程。相比于可以借鉴宏表情检测技术的微表情监测,微表情的识别技术具有更大的研究挑战,这也是目前微表情领域的研究重点。
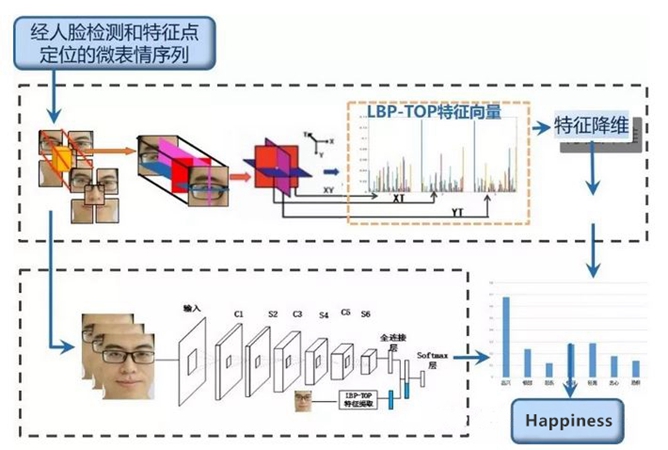
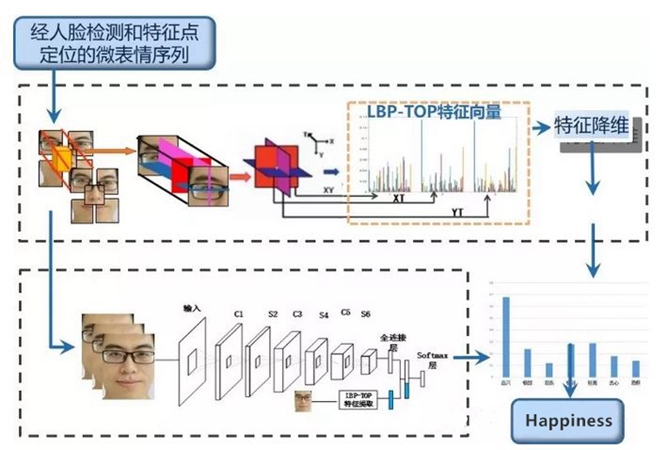
由于微表情持续时间短和动作幅度小两大识别难点,目前的识别率仍有很大的提升空间。传统大多采用基于聚类的方法,联合3D高斯滤波器和K均值算法,来测量微表情的开始、峰值和结尾阶段,然而在这个方法中,聚类的数量很难决定。另一种基于分类的方法可以利用时空局部纹理描述器来表示特征,随后通过支持向量机SVM(Support Vector Machine, SVM)分类器来进行分类。这些工作大都致力于在特征的层面上改进微表情识别的性能,取得了一定的性能改进,但是仍然欠缺计算得到特征的可解释性。为此,我们提出一种基于深度学习的微表情识别方法、深度学习的概念由Hinton等人于2006年提出,属于机器学习研究中的一个新的领域,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。算法本质是对数据的表征学习,目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。例如,针对一幅图像,观测值可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务。按照训练样本标签的有无,深度学习可以分为有监督学习(supervised learning)和无监督学习(unsupervised learning)。
深度学习理论基础是机器学习中的分散表示(distributed representation)。分散表示假定观测值是由不同因子相互作用生成。在探究这种相互作用的过程中,深度学习受到人类视觉原理的启发。人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。因而,深度学习也采用逐层依次进行,逐步泛化抽象的基本结构:假定不同因子相互作用的过程可分为多个层次,代表对观测值的多层抽象。不同的层数和层的规模可用于不同程度的抽象。更高层次的概念从低层次的概念学习得到。这一分层结构常常使用贪婪算法逐层构建而成,并从中选取有助于机器学习的更有效的特征。
基于深度学习的微表情识别工作流程包括以下四个步骤:
1) 准备数据集:包含微表情的视频片段采集、视频图像归一化处理、训练/验证/测试集分割等;
2) 设计学习模型:选择基本模型框架为卷积神经网络CNN+循环神经网络RNN、调整网络层数、确定损失函数、设计学习率等超参数;
3) 训练模型:将模型输出误差通过BP算法反向传播,利用随机梯度下降SGD或Adam算法优化模型参数;
4) 验证模型:利用未训练的数据验证模型的泛化能力,如果预测结果不理想,则需要重新设计模型,进行新一轮的训练;
至今已有数种成熟的深度学习模型,包括深度神经网络DNN、卷积神经网络CNN和深度置信网络DBN和递归神经网络RNN等。在语音识别、机器视觉、自然语言处理、生物信息学等领域得到广泛应用、并且取得了显著效果。
微表情分析是目前极具前瞻性的研究领域,人工智能深度学习模型的引入,较大提升了微表情识别性能,也将加速该领域的应用进展。但是,由于深度学习的黑盒特性,难以对微表情识别的特征提取过程进行定性研究,为此,仍需要进一步加强对深度学习模型的可视化技术研究,提高学习模型的可靠性分析并在可解释性的基础上进一步提高微表情识别准确度。